
본 포스트는 감성 분석(Sentiment Analysis)과 감성 분석 데이터셋 구축에 대한 내용을 다룹니다.
1. Background
1-1. Sentiment Classification
감성 분석(Sentiment Analysis)이란 텍스트에 들어있는 감성, 감정 등의 주관적 정보를 평가 및 분석하는 연구 분야입니다. 이를 통해 주어진 텍스트가 긍정적인지, 부정적인지 등을 분류(Classification) 합니다.
이 영화는 정말 명작이네요. 몇 번을 봐도 재미있습니다. (긍정)
생각보다 영화 스토리가 지루하고 재미없네요. (부정)
최근 NLP(natural language processing) 분야에서 BERT, GPT와 같은 transformer 기반의 딥러닝 모델이 많이 발전되었습니다. 우리는 음식점 리뷰 데이터를 기반으로 한국어 감성 분석 데이터 셋을 구축하고, BERT를 사용하여 감성 분류를 진행해 보았습니다.
1-2. Pre-trained Language Models and BERT
NLP에서 transfer learning이란, 대량의 corpus로 pre-train된 언어 모델을 다른 task에 재사용하는 기법입니다.
대규모의 데이터를 통해 학습된 pre-train 모델은 다양한 종류의 task를 수행할 수 있도록 훈련되었습니다. 이렇게 훈련된 모델에 우리가 원하는 특정한 task를 더 잘 수행할 수 있도록 추가적인 훈련을 해 줌으로써 큰 노력을 들이지 않고도 좋은 성능을 낼 수 있는 모델을 만들 수 있습니다.
특히, 우리가 사용한 BERT 모델에서는 다음 문장 맞히기(Next Sentence Prediction, NSP)와 빈칸 채우기(Masked Language Model, MLM)를 훈련시키는 방식으로 pre-train을 진행합니다. 이렇게 훈련된 모델에 덧붙여, 우리가 해결하고자 하는 특정 task를 학습시키기 위해 BERT의 출력층에 추가적인 레이어를 쌓고, 이에 대응하는 데이터를 사용하여 훈련하는 fine-tuning 과정을 거치게 됩니다.
Single Text Classification
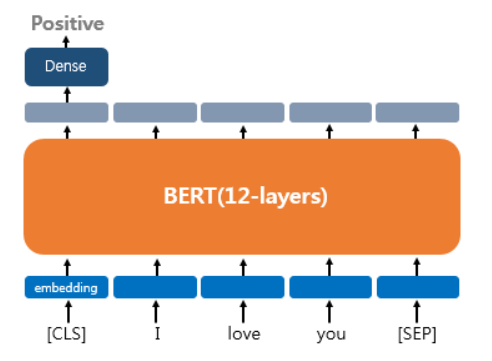
예를 들어, 대표적인 downstream task 중 하나인 single text classification은 입력된 문서를 긍정, 부정으로 분류하는 task입니다. 이를 위해 문장이 시작하는 곳에 위치한 [CLS] 토큰에 대응하는 출력층에 밀집층(Dense layer, FCN)을 추가해 주어 그 결과값을 반환할 수 있도록 합니다.
후술할 데이터셋인 KR3에 대한 sentiment classification 역시 이와 비슷한 방식으로 진행할 것입니다.
2. KR3 (Korean Restaurant Review with Ratings)
2-1. Survey of Sentiment Classification Datasets
감정 분류(sentiment classification)는 NLP의 가장 기본적인 태스크로, 여러 데이터셋이 이미 존재합니다. 영어 데이터셋 중 가장 유명한 것은 SST-2로, GLUE라는 대표적인 NLU(Natural Language Understanding) 벤치마크 중 하나이기도 합니다. 한국어 데이터셋 중 가장 유명한 것은 NSMC입니다. SST-2와 NSMC 모두 영화 리뷰로 구성되어 있습니다. 아래는 여러 감정 분류 데이터셋을 정리한 표입니다.
| Name | Language | #(reviews) | #(classes) | Domain | Note |
|---|---|---|---|---|---|
| SST-2(5) (Socher et al., 2013) | English 🇺🇸 | 67K | 2(5) | Movie | SST-2 is one of GLUE benchmarks. (Wang et al., 2019) |
| IMDb (Mass et al., 2011) | English 🇺🇸 | 50K | 2 | Movie | |
| NSMC* (Naver Sentiment Movie Corpus) | Korean 🇰🇷 | 200K | 2 | Movie | Benchmark used for HyperCLOVA (Boseop Kim et al., 2021) |
| Yelp-2(5) | English 🇺🇸 | 60K(70K) | 2(5) | Restaurant | |
| Amazon-2(5) | English 🇺🇸 | 4M(3.7M) | 2(5) | Retail | |
| Naver Shopping** | Korean 🇰🇷 | 200K | 2 | Retail | |
| Steam** | Korean 🇰🇷 | 100K | 2 | Game | |
| KR3 (Ours) | Korean 🇰🇷 | 460K(+190K) | 2 | Restaurant | Additional 190K is unlabeled |
*e9t/nsmc: Naver sentiment movie corpus (github.com)
**corpus/sentiment at master · bab2min/corpus (github.com)
데이터셋의 기본적인 정보에 더해, 각 데이터셋이 만들어진 방식에도 주목할 필요가 있습니다. SST는 인간이 직접 레이블링을 한데 비해, NSMC는 웹에 주어진 별점과 리뷰의 쌍을 토대로 구성했습니다.
| Name | Annotation | #(Original Classes) | #(Constructed Classes) | Class Balance |
|---|---|---|---|---|
| SST | Human annotator | 7 | 2 or 5 | Balanced |
| IMDb | Rating-Review pair from the web | 10 | 2 | Strictly balanced to 50:50 |
| NSMC | Rating-Review pair from the web | 10 | 2 | Strictly balanced to 50:50 |
웹에 주어진 별점은 주로 이진(binary) 분류가 아니기에, 이를 긍정/부정으로 재분류할 필요가 있습니다. IMDb와 NSMC는 아래 기준에 따라서 긍정과 부정을 분류했으며, 애매한 별점의 리뷰는 아예 포함시키지 않았습니다.
| Name | Construction Criteria |
|---|---|
| IMDb | Negative: rating ≤ 4, Positive: rating ≥ 7 |
| NSMC | Negative: rating ≤ 4, Positive: rating ≥ 9 |
2-2. KR3 for Restaurant Review Sentiment Classification
기존 한국어 감정 분석 관련 데이터셋의 타겟 영역을 피해, 맛집 리뷰 감정 분석 데이터셋을 구축했습니다. 맛집 리뷰의 경우 긍 부정을 평가하는 단어 및 표현이 주로 포함이 되고 실제 사용자들도 식당이 맛집인가를 유추하는 용도로 해당 식당의 후기를 종종 살펴보곤 합니다. 이에, 식당의 정보 및 평가 후기를 모아놓은 웹사이트들의 사용자 리뷰와 별점을 크롤링 및 전처리를 통해 KR3(Korean Restaurant Review with Ratings) 데이터셋을 구성했습니다.
2-3. Crawling & Preprocessing the Review of Restaurant
각 리뷰 사이트마다 맛집을 검색하는 방법, 리뷰에 접근하는 절차, 평가 방식, 더 많은 리뷰를 불러오는 방법 등이 다르기 때문에 리뷰 사이트 별 크롤링 코드를 각각 다르게 했습니다. 크롤링 자동화에는 공통적으로 selenium 파이썬 라이브러리를 사용했고, 해당 리뷰 사이트의 검색쿼리에 대한민국 법정동명의 하위 집합 (특별시, 광역시의 경우 ‘구, 군’, 도의 경우 ‘시, 군’) 또는 지하철역 명을 입력했습니다. 아래는 맛집 리뷰 사이트 중 일부의 데이터이고 긴 문장은 중략했습니다.
| Region | Rating | Category | Review | |
|---|---|---|---|---|
| 0 | 종로구 | 3 | 한정식 / 백반 / 정통 한식 | 한줄평: 왜 이렇게 평점이 높은지 이해가 가는 집\n- 주문 메뉴: 병어찜 중,… |
| 1 | 종로구 | 3 | 한정식 / 백반 / 정통 한식 | “얼마나 맛있는지 알지 못 할거야” |
| … | … | … | … | … |
| 267546 | 서귀포시 | 2 | 카페 / 디저트 | 60, 70년대 향취 가득한 음악들과 카페 분위기가 잘 어울리는 카페. 디저트나 카… |
| 267547 | 서귀포시 | 2 | 카페 / 디저트 | 제주도 모슬포에 위치한 카페!\n분위기 너무 좋고 조용한 모슬포에서 즐겼던 디저트 … |
전처리 과정은
1) 맛집 별로 ‘지역’, ‘별점’, ‘카테고리’, ‘리뷰’를 크롤링 했으며,
2) 중복되는 데이터는 제거하고,
3) 각 사이트의 데이터를 통합했습니다.
4) 통합 이후 특수 문자, 특수 기호, 이모티콘 등 모델링에 불필요할 문자를 제거했습니다.
5) 리뷰의 길이가 3 미만, 4000 초과인 데이터(861건)는 제외했습니다.
6) 또한, 텍스트의 맞춤법을 검사하는 hanspell 라이브러리를 사용해 네이버 맞춤법 검사기에 맞게 정제했습니다.
2-4. KR3 Construction Strategies
인간이 직접 레이블링을 하는 것은 시간과 노력이 필요하기 때문에, KR3 데이터에서는 IMDb, NSMC와 같이 기존 리뷰의 별점을 기준으로 긍정/부정으로 재분류 했습니다. 각 리뷰 사이트마다 별점의 기준이 다르기 때문에, 각각 아래와 같은 기준에 따라 분류했습니다. 아래 기준은 인간인 저희가 리뷰들을 직접 읽어보며 설정했습니다.
| Source | 0 (Negative) | 1 (Positive) | 2 (Ambiguous) |
|---|---|---|---|
| 다이닝코드 | 0 / 1 / 2 | 4 / 5 | 3 |
| 망고플레이트 | ‘별로’ | ‘맛있다’ | ‘괜찮다’ |
| 식신 | 1.0 / 1.5 / 2.0 | 4.5 / 5.0 | 2.5 / 3.0 / 3.5 / 4.0 |
| 카카오맵 | 1 / 2 | 4 / 5 | 3 |
| 포잉 | 0 / 1 | 4 / 5 | 2 / 3 |
2-5. Description of KR3 and Comparison with NSMC
KR3는 긍정 388,111개, 부정 70,910개로 총 459,021개의 데이터에 추가로 미분류 182,741개를 제공하는 반면 NSMC의 경우 긍정, 부정 각각 100,000개를 제공합니다. KR3가 NSMC보다 2배, unlabeled 데이터 포함 시 3배 더 많은 리뷰를 포함하고 있는 것입니다.
또한 클래스 간 균형이 맞춰진 NSMC와 달리, KR3에는 클래스 불균형이 존재합니다. 저희는 웹 크롤링으로 얻어진 데이터 분포를 인위적으로 조작하지 않고, 그대로 유지했습니다. 이는 최근 NLP 모델의 성능이 향상됨에 따라 클래스 불균형이라는 조금 더 어려운 세팅에서도 유의미한 성능을 낼 수 있으리라는 점, KR3가 감성 분류 외의 다른 목적으로 사용/재가공될 수 있다는 점을 고려한 것입니다.
KR3의 리뷰 길이 역시도 NSMC보다 훨씬 긴데, 이 역시도 최근 NLP 모델의 성능이 향상되어 더 긴 인풋을 처리할 수 있다는 점을 반영한 것입니다.
| Source | KR3(ours) | NSMC | Naver Shopping | Steam |
|---|---|---|---|---|
| 0 (Negative) | 70,910 | 100,000 | 100,037 | 49,996 |
| 1 (Positive) | 388,111 | 100,000 | 99,963 | 50,004 |
| Total | 459,021 (+182,741) | 200,000 | 200,000 | 100,000 |
| Avg. word | 32 | 8 | 9 | 11 |
| Std. word | 44 | 7 | 7 | 8 |
2-6. Legal Issues, License, and Release
저희는 KR3의 비상업적 이용 및 배포가 저작권법의 “공정 이용”에 해당된다고 결론지었습니다. 그와 더불어, 저희는 웹 크롤링 과정에서 어떠한 웹사이트의 이용약관에도 동의하지 않았다는 점을 밝힙니다. 이는 저희가 크롤링 시 각 웹사이트에 로그인을 하지 않았다는 뜻입니다. 따라서, 이용약관 상의 크롤링에 대한 제약은 저희와 무관합니다.
KR3의 라이센스는 CC BY-NC-SA 4.0입니다. 데이터셋 사용 시 원작자의 출처를 밝혀야 하며(BY), 상업적 이용을 금지하고(NC), 데이터셋 가공 후 재배포 시 동일 라이센스를 사용해야 합니다(SA).
저희는 데이터셋을 Kaggle([KR3: Korean Restaurant Reviews with Ratings | Kaggle])과 Hugging Face([Wittgensteinian/KR3 · Datasets at Hugging Face])에 배포하였습니다.
3. Tuning Experiments
3-1. Baseline Fine-tuning using BERT
저희는 BERT(Devlin et al., 2018)를 fine-tuning하여 이를 베이스라인으로 설정하였습니다. Pre-trained BERT는 hugging face의 bert-base-multilingual-cased · Hugging Face를 활용하였습니다. 매 epoch마다 학습 이후 validation set으로 평가(evaluate)를 하고, 이 중 가장 좋은 성능 지표를 모델의 최종 지표로 리포팅합니다.
결과와 구체적인 설정은 다음과 같습니다.
| Metric | f1 | accuracy | train loss* | validation loss* |
|---|---|---|---|---|
| Fine-tuned BERT | 0.9266 | 0.9624 | 0.084 | 0.113 |
*loss from the epoch in which f1 is the highest.
| Configuration | epoch | batch size | learning rate (Adam) |
|---|---|---|---|
| Fine-tuned BERT | 5 | 8 | 1e-5 |
💡 컴퓨팅 자원과 시간의 제약으로, 여러 하이퍼파라미터들을 실험해보지 못했습니다. 제시된 하이퍼파라미터는 최적이 아닐 수 있습니다.
⚠️ KR3 자체가 불균형한 데이터셋이므로, 성능 지표들을 볼 때도 주의할 필요가 있습니다. 따라서 저희는 accuracy보다 f1을 주 성능 지표로 사용했습니다. 저희가 리포팅하는 f1은 macro f1, 즉 class=0을 양성(positive)로 두었을 때와 class=1을 양성(positive)로 두었을 때의 평균입니다. 데이터가 부족한 class=0이 양성일 때의 f1은 0.88, 반대는 0.98로, 어느 정도 차이가 난다는 점 역시 저희 프로젝트에서는 중점적으로 다루지 않으나, 참고해야할 사항입니다.
3-2. Cross-domain pre-training and fine-tuning
Don’t Stop Pretraining: Adapt Language Models to Domains and Tasks (Gururangan et al., 2020)에서는 DAPT(Domain-Adaptive PreTraining) 방식과 TAPT(Task-Adaptive PreTraining) 방식으로 기존 pre-trained language model에 additional pre-training을 했을때의 효과를 보였습니다. 저희는 TAPT의 효과를 확인하기 위해 Review 데이터 도메인에 여러 task 데이터를 사용해 cross pre-training, fine-tuning을 적용했습니다.
Additional Pre-training에는 기존 bert-multilingual-base 모델에 AdamW optimizer(learning rate=1e-3)를 사용해 NSP 비율: 0.5, MLM 비율: 0.15로 세팅한 후 100 epoch 동안 학습을 진행했습니다.
Fine-tuning에는 Adam optimizer(learning rate=5e-5)를 사용하였고, early stopping patience를 5로 설정해 valid loss가 5 epoch 동안 감소하지 않으면 학습을 중지하는 전략을 사용했습니다.
| 추가 pre-train \ fine-tune | KR3 | NSMC | ||
|---|---|---|---|---|
| F1-score(macro) | Accuracy | F1-score(macro) | Accuracy | |
| no pre-training (original bert) | 0.8709 | 0.9348 | 0.8616 | 0.8617 |
| KR3 | - | - | 0.8748 | 0.8749 |
| NSMC + Naver Shopping + Steam | 0.9325 | 0.9653 | - | - |
위 결과를 봤을때, Review 도메인의 다른 태스크의 데이터셋으로 추가 pre-training을 했을때 성능이 더 향상하는 것을 볼 수 있습니다.
3-3. Parameter-efficient Tuning
Parameter-efficient tuning은 최근 pre-trained model의 크기가 기하급수적으로 커지면서 주목을 받고 있는 주제입니다. Downstream task에 fine-tune된 모델은 기존의 pre-trained model과 크기가 같기에, 여러 태스크와 데이터가 있는 경우 모델을 저장하기 위해 필요한 총 저장공간은 매우 커집니다. Parameter-efficient tuning의 목표는 더 적은 파라미터만을 학습하여 downstream task에 대해서 fine-tuning과 비슷한 성능을 내는 것입니다. 대표적인 parameter-efficient tuning 방법들은 다음과 같습니다.
| Method | Papers |
|---|---|
| Adapter | - Parameter-Efficient Transfer Learning for NLP. Houslby et al. 2019. </br> - Adapterdrop: On the efficiency of adapters in transformers. Ruckle et al. 2020. </br> - AdapterFusion: Non-Destructive Task Composition for Transfer Learning. Pfeiffer et al. 2021. |
| Continuous Prompt Tuning | - Prefix-Tuning: Optimizing Continuous Prompts for Generation. Li et al. 2021. </br> - GPT Understands, Too. Liu et al. 2021. |
| Low-Rank Adaptation (LoRA) | - LoRA: Low-Rank Adaptation of Large Language Models. Hu et al. 2021. |
저희는 이 중 BERT와 같은 bidirectional language model에 적합하다고 생각되는 Adapter와 LoRA를 적용해보았습니다. Adapter는 pre-trained 모델 layer 사이에 들어가는 학습 가능한 모듈입니다. Houslby et al, 2019에서는 트랜스포머의 각 서브레이어(sub-layer) 뒤에 bottleneck 구조의 adapter를 추가하였습니다. 본 논문에서 BERT에 대해서 GLUE를 기준으로 실험을 진행한 결과, pre-trained 모델 파라미터 개수의 3.6%만을 활용하면서도 성능 손실은 0.4%에 그쳤습니다.
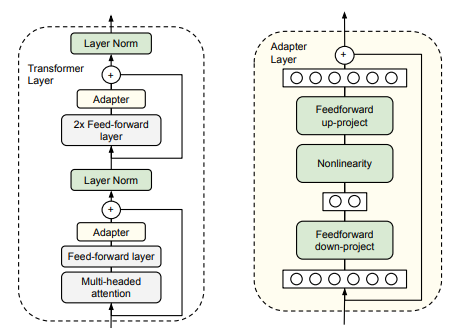
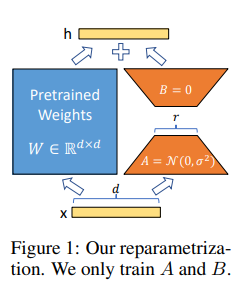
Adapter의 구조(좌측, Houlsby et al. 2019)과 LoRA(우측, Hu et al. 2021)
LoRA의 핵심은 ‘low-rank’입니다. Pre-trained weight가 $W$이며, fine-tuning은 이를 $W’ = W + \Delta W$로 업데이트한다고 했을 때, low-rank adaptation(LoRA)는 fine-tuning에서 새로 학습되는 ${\Delta}W$의 rank가 낮다고 가정합니다. 즉, $\Delta W = BA$로 분해(decompose)할 수 있다는 것입니다. 따라서 LoRA는 $\Delta W$를 학습하는 대신, $A$와 $B$를 학습합니다. Hu et al, 2021에서는 트랜스포머 내의 attention matrix에만 LoRA를 적용하고 있습니다.
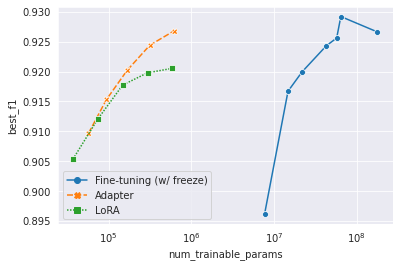
실험 결과는 위와 같습니다. 파란 점들 중에는 전체 fine-tuning 외에도 일부 layer를 얼린 fine-tuning이 있습니다. Fine-tuning (w/ freeze)의 가장 좋은 결과와 비교했을 때, Adapter와 LoRA는 파라미터의 수를 0.9%~0.06%까지 줄이면서도, 99.7%~96.4%의 성능을 유지했습니다. KR3를 활용한 감성 분류에서, 두 방법을 통한 성공적인 parameter-efficient tuning을 보인 것입니다.